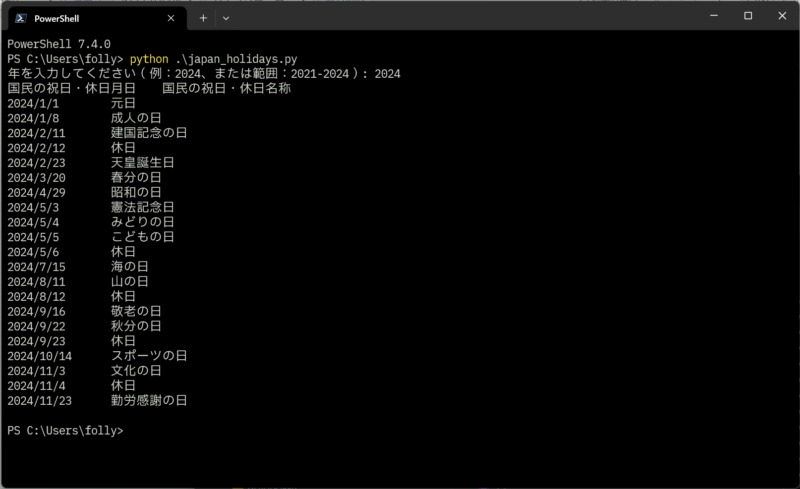
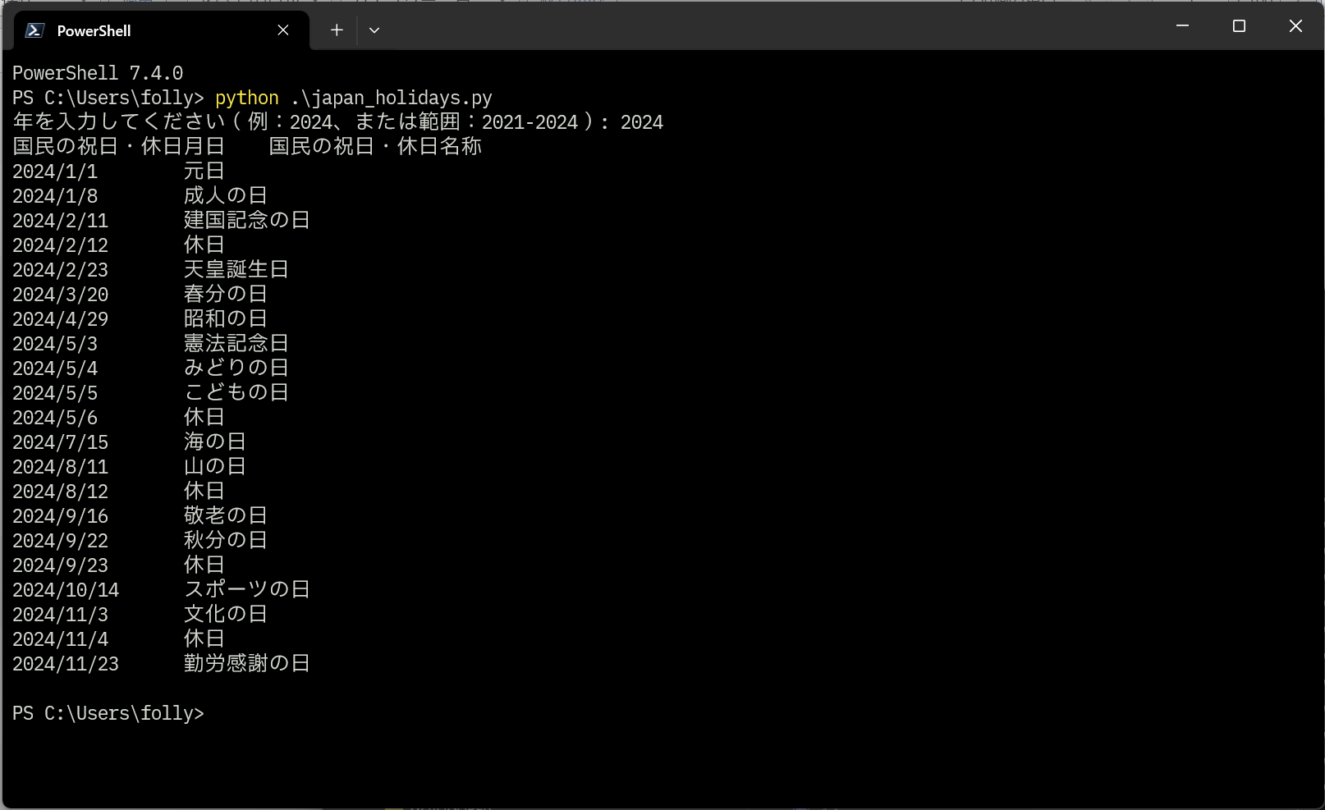
国民の祝日を調べる
毎年1回だが、祝日を調べて休日考慮のExcelなどのデータにする。
総務省のサイトで調べてExcelに貼って・・・とやっていたが、ちょっとでも早くなるかな?と思い、pythonで書いてみた。(chatGPTに殆ど書いてもらえた。
CKANというデータ管理システムでファイルのURIが管理されているそうなので、そこからアドレスを取得しています。
使い方:
japan_holidays.pyを実行するとコンソール出力します。引数にファイル名を指定すると、タブ区切りの出力をします。
japan_holidays.py shukujitsu.csv
のようにして書き出してもらうと、Excelでcsv読み込みして簡単に使用できます。
会社のお休みとして使うときは年末年始の1月2,3日などは国民の祝日に関する法律の対象ではないので、気をつけましょう。
#!python3
# coding: utf-8
"""
日本の祝日をデジタル庁のデータカタログから取得します
必要なパッケージ:
- os, sys, requests, configparser, pandas
ToDo:
動作チェック
"""
import configparser
import os
import sys
import pandas as pd
import requests
class HolidayDataDownloader:
def __init__(self, dataset_id, local_filename, ini_filename):
self.dataset_id = dataset_id
self.local_filename = local_filename
self.ini_filename = ini_filename
def download(self):
dataset_info_url = f"https://data.e-gov.go.jp/data/api/action/package_show?id={self.dataset_id}"
response = requests.get(dataset_info_url).json()
if not response.get("success", False):
print(f"APIからのレスポンスが失敗しました。エラーメッセージ: {response.get('error')}")
sys.exit()
resource = response["result"]["resources"][0]
file_url = resource["url"]
last_modified = (
resource["last_modified"]
if resource["last_modified"]
else resource["created"]
)
config = configparser.ConfigParser()
if os.path.exists(self.ini_filename):
config.read(self.ini_filename)
local_last_modified = config.get("DEFAULT", "last_modified", fallback="")
if local_last_modified == last_modified:
return
response = requests.get(file_url)
with open(self.local_filename, "wb") as file:
file.write(response.content)
config["DEFAULT"] = {"last_modified": last_modified}
with open(self.ini_filename, "w") as configfile:
config.write(configfile)
class HolidayDataExtractor:
def __init__(self, filename):
self.filename = filename
def extract_for_year(self, year_range):
holidays_df = pd.read_csv(self.filename, encoding="shift_jis")
holidays_df["年"] = pd.to_datetime(holidays_df["国民の祝日・休日月日"]).dt.year
year_parts = year_range.split("-")
if len(year_parts) == 1:
year = int(year_parts[0])
filtered_df = holidays_df[holidays_df["年"] == year]
else:
start_year, end_year = map(int, year_parts)
filtered_df = holidays_df[
(holidays_df["年"] >= start_year) & (holidays_df["年"] <= end_year)
]
if filtered_df.empty:
return None
else:
return filtered_df[["国民の祝日・休日月日", "国民の祝日・休日名称"]]
def get_user_input():
return input("年を入力してください(例:2024、または範囲:2021-2024): ")
def main():
dataset_id = "cao_20190522_0002"
local_filename = "japan_holidays.csv"
ini_filename = "japan_holidays.ini"
downloader = HolidayDataDownloader(dataset_id, local_filename, ini_filename)
downloader.download()
extractor = HolidayDataExtractor(local_filename)
year_range = get_user_input()
holidays = extractor.extract_for_year(year_range)
if holidays is None or holidays.empty:
print("取得データ範囲にありません。")
else:
output_str = holidays.to_csv(
index=False, sep="\t", header=True, lineterminator="\n"
)
print(output_str)
if len(sys.argv) > 1:
output_filename = sys.argv[1]
with open(output_filename, "w", encoding="utf-8", newline="") as file:
file.write(output_str)
if __name__ == "__main__":
main()